2026-06-27 · 12 min · generative-models · neuromorphic · physics · image-generation · explainer
Every image model you know is built from the same parts: neural-network layers, a lot of matrix multiplies, and — for the generative step — either a diffusion schedule or an adversary. Un-0 throws all of that out. Its computational core is a population of coupled oscillators, and the generative step is just letting them settle.
This is the first release from Unconventional AI, the company Naveen Rao (ex-Databricks AI head, founder of Nervana and MosaicML) started with Michael Carbin and Sara Achour, on a $475M seed. The thesis is one sentence: physics as a computational primitive. Instead of simulating a dynamical system on a von Neumann machine, run the dynamical system directly in analog silicon, and let the chip's physics be the computation — chasing brain-like (~20 W) efficiency.
Un-0 is explicitly the "hello world" of that program: a proof, in software simulation, that the math produces real images. The chip doesn't exist yet. Keep that line bright; I'll come back to it.
Here is the thing itself: a field of oscillators, each pulled toward its neighbours. Raise the coupling and watch incoherent speckle organise into travelling waves. That self-organisation — not a matrix multiply — is the computation Un-0 runs.
From random phase the field is pure speckle (low K). Raise the coupling and neighbours fall into step, carving out travelling spiral waves and chimera-like domains where order and chaos coexist — the structure Un-0 decodes into pixels.
The primitive: Kuramoto oscillators
An oscillator is just a phase turning at its own natural frequency . Couple a population of them and each one also feels a pull toward its neighbours' phases. That's the Kuramoto model:
is the coupling strength. The behaviour has a sharp phase transition. Below a critical , everyone runs at their own frequency and the phases scatter — incoherent. Above it, the population spontaneously synchronizes into one travelling cluster. The standard measure is the order parameter
where is total incoherence and is full lock. You've seen this in the physical world — pendulum metronomes started out of step on a shared, freely-moving base pull each other into perfect synchrony:
Each oscillator can be drawn as its own dial. Drag through the transition and watch the hands go from smeared to locked, and climb:
At K=0 every dial runs at its own natural frequency ωᵢ and the hands smear across all phases (r≈0). Raise K and each hand feels a pull toward the population’s mean phase proportional to how synchronized it already is — a positive feedback that snaps the whole grid into lockstep past a critical coupling. Un-0 shapes exactly this settling to encode an image.
The point for Un-0: that transition, and the rich partially-synchronized regime around it, is a programmable dynamical system. If you can shape the coupling and the frequencies, the settled phase pattern can encode something — like an image.
The pipeline: condition, evolve, read out
Un-0's main class is a ConditionalImplicitKuramotoGenerator. There's no denoising
schedule, no adversary, no iterative refinement loop in the diffusion sense — just an
ODE you integrate forward once.
Step by step:
- Initialize every oscillator's phase randomly.
- Condition on the class label through a separate oscillator array that couples one-directionally into the main population — the label bends the dynamics without being bent back.
- Evolve the coupled ODE forward for a fixed time with explicit Euler integration. This is the entire "generation" — no schedule, no sampler loop.
- Read out the settled phases via .
- Decode with a small conventional network — capped at ≤15% of total parameters — to produce pixels.
Training learns the coupling matrix , the natural frequencies , and the decoder weights, via a "drifting loss" that uses a frozen DINOv2 feature extractor, with AdamW. So the learning is conventional gradient descent; what's unconventional is that the thing being learned is the physics of a dynamical system, not a stack of attention layers.
Training: differentiating through the dynamics
The subtle part is how you get gradients into an ODE. The forward pass is the Euler integration of the Kuramoto system — a long chain of -coupled updates — and the decoder reads the final state. Because every step is differentiable, you can backpropagate through the unrolled trajectory and update , , and the decoder end-to-end. The "drifting loss" supervises in a perceptual feature space (a frozen DINOv2 encoder) rather than raw pixels, which is what lets a tiny decoder — capped at ≤15% of parameters — get away with so little work: the oscillator field is doing the heavy lifting, and the loss only has to match high-level features, not paint exact RGB.
Two things fall out of this design that are worth stating plainly:
- Capacity lives in the coupling. Almost all the model's parameters are the coupling matrix (it's in the oscillator count ), which is exactly why FID improves monotonically as you scale — you're literally adding interaction terms to the dynamical system.
- The natural frequencies are learned, not fixed. The model gets to choose each oscillator's intrinsic rhythm, so it can place itself wherever in the synchronize/desynchronize landscape is most useful for a given class.
Oscillators vs diffusion
It's tempting to file Un-0 under "another iterative generator," but the comparison is instructive precisely because of how it differs:
| Diffusion model | Un-0 (oscillators) | |
|---|---|---|
| Generative step | reverse a noising schedule, T denoising passes | integrate one coupled ODE to time T |
| Core compute | matrix multiplies in NN layers | sin-coupled phase updates |
| Conditioning | cross-attention / adaLN on the class | one-directional coupling from class oscillators |
| Stochasticity | injected noise at each step | random initial phases only |
| Why it might be efficient | — | the physics can run in analog silicon |
A diffusion model spends its compute pushing tensors through learned layers many times. Un-0 spends its compute letting a physical system relax. On a GPU that's a wash at best — more on that below — but the bet is that the relaxation is free when the substrate is the right kind of analog hardware.
Does it actually generate images?
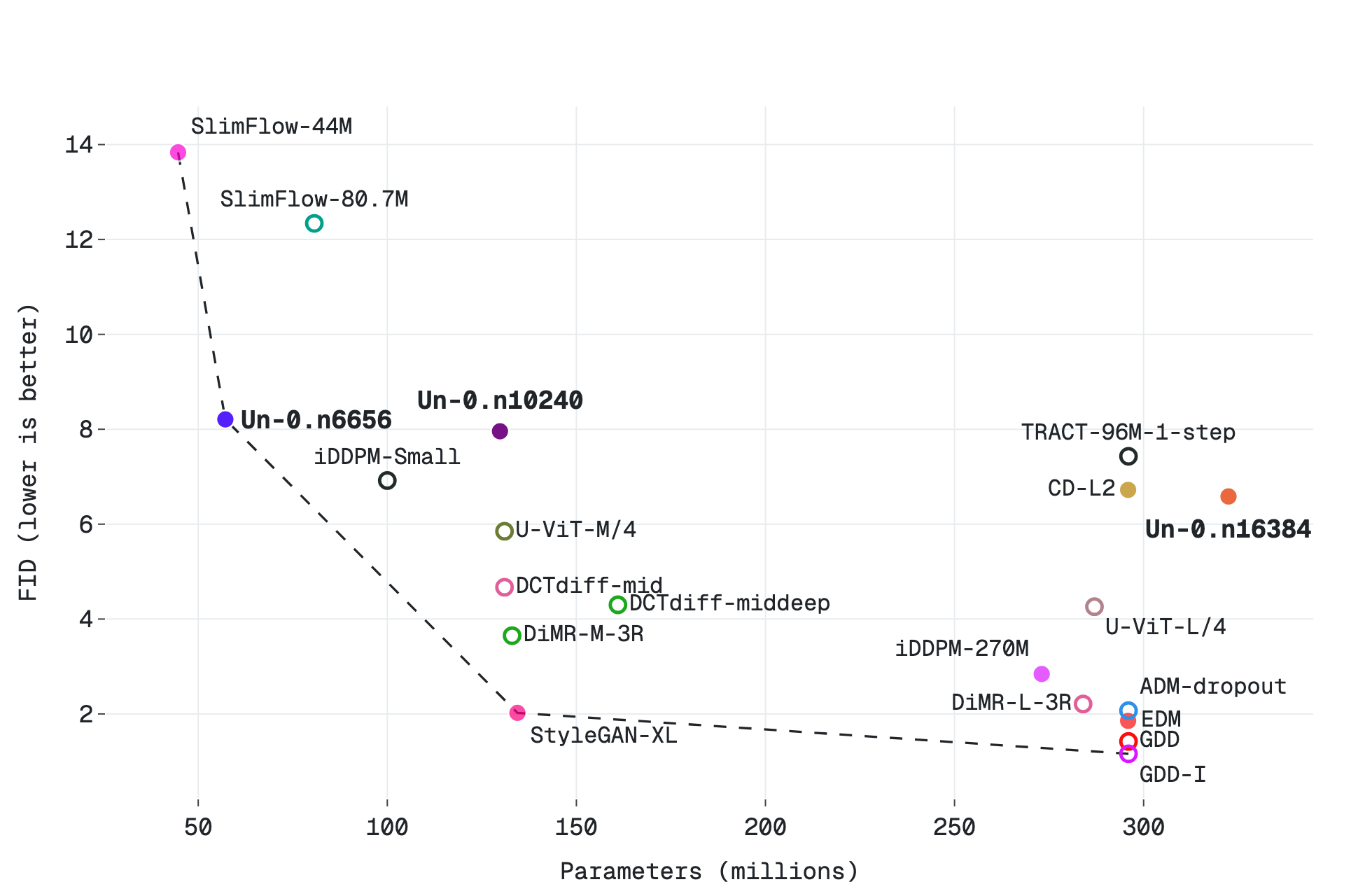
Yes — and the honest version is "yes, modestly". Un-0 is class-conditional and low-res, and the company is upfront that it underperforms state-of-the-art generators like EDM. The headline is FID 6.74 on ImageNet 64×64, which they frame as matching early conventional generators.

And here is the generation happening — a row of samples resolving out of the oscillator field as the ODE integrates forward in time. There's no denoising loop; this is the population relaxing toward its conditioned attractor and the decoder reading it out frame by frame:
FID scales the way you'd hope with oscillator count (more oscillators, lower FID):
| Dataset | config | params | FID (↓) |
|---|---|---|---|
| CIFAR-10 32×32 | n1024 | 1.3M | ~11.0 |
| CIFAR-10 32×32 | n2048 | 4.9M | ~9.3 |
| CIFAR-10 32×32 | n4096 | 19.4M | ~8.8 |
| ImageNet 64×64 | n6656 | 57M | ~8.4 |
| ImageNet 64×64 | n10240 | 130M | ~8.0 |
| ImageNet 64×64 | n16384 | 322M | 6.74 |
The same monotone scaling holds on CIFAR-10, where even a 1.3M-parameter field already reaches a usable FID:
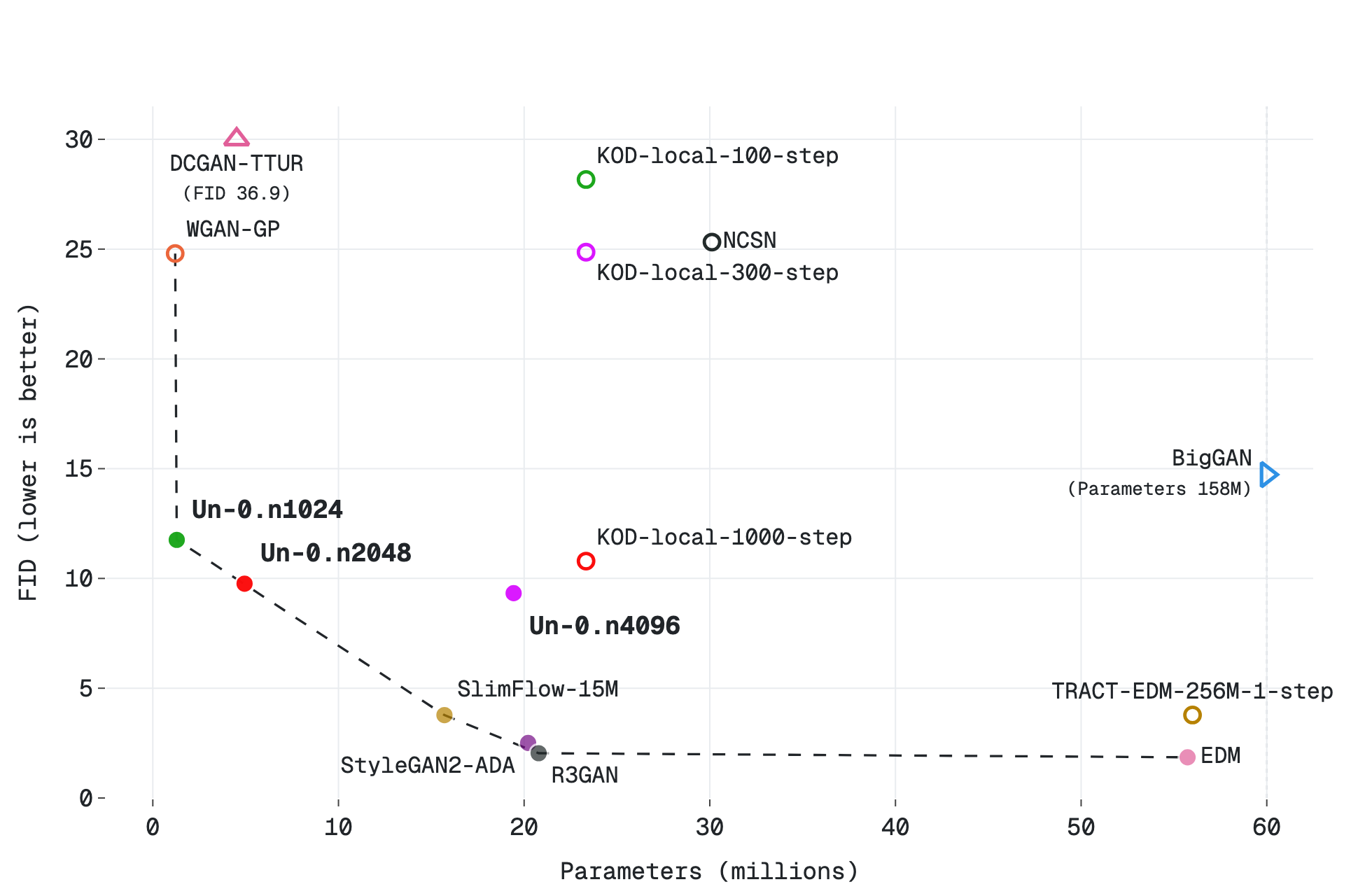
Note the FID values wobble slightly between the blog and the repo README (e.g. 8.41 vs 8.36) — these are self-reported, not third-party-reproduced, so treat them as approximate. The compute is non-trivial too: the largest ImageNet run is reported around 640 B200-GPU-hours — simulating the oscillators on conventional GPUs is the expensive part, which is exactly the cost the proposed chip is meant to erase.
The hardware bet
This is where the whole thing either pays off or doesn't. Today's accelerators are von Neumann machines: weights live in memory, you stream them to compute units, multiply, and write back. That shuffle — not the arithmetic — is where most of the energy goes.
Unconventional AI's proposal is to build the oscillators in physical silicon (CMOS ring oscillators are the usual candidate), so that the coupled dynamics happen rather than being computed. There's no weight streaming because the coupling is the wiring; the system's settling to a synchronized state is the forward pass. The aspiration is brain-like efficiency — order-of-tens-of-watts, against data-center GPUs — and the "1000×" figure is a projection of what that substrate could do relative to simulating the same ODE on a GPU.
It's a real idea with real lineage — analog and neuromorphic computing has chased this for decades — and the team (Naveen Rao, plus Michael Carbin from MIT and Sara Achour from Stanford on the hardware/compiler side) is credible. But it is, today, a proposal. The repo says chip schematics are "coming soon".
The part to keep straight
So separate two claims cleanly. Demonstrated today, in simulation: a coupled-oscillator ODE, conditioned and evolved once, decodes into recognizable class-conditional images at FID 6.74 (ImageNet-64). Proposed, not yet built: the analog oscillator chip whose physics would run that ODE for ~1000× less energy. The first is a real, open, checkable result. The second is a hardware vision — credible given the team and funding, but unbuilt and unverified.
What I make of it
- The idea is genuinely different, not a reskin. Replacing layers + a diffusion schedule with "set up a dynamical system and let it settle" is a real departure. The generative step is an ODE integration, and the learned object is the physics itself.
- The demo is honest and modest. FID 6.74 on ImageNet-64 is a proof-of-concept that the math closes, deliberately framed as a "hello world", explicitly behind SOTA. That honesty is worth more than a cherry-picked headline.
- The whole bet lives in the hardware that isn't here. On a GPU, simulating oscillators is slower and costlier than just running a normal generator — the entire payoff is conditional on the analog chip materializing and delivering the projected efficiency. Until silicon exists, "1000×" is a hypothesis, and the right way to read Un-0 is as a credible research demonstration of physics-based generative computing — not a shipping efficiency win.
Built on Unconventional AI's Un-0 technical writeup and the MIT-licensed Un-0 code. Benchmarks are self-reported; the analog-hardware efficiency claim is a founder projection, not a measured result.