2026-06-23 · 12 min · llm · multi-agent · orchestration · reinforcement-learning · explainer
No single LLM wins everywhere. One model leads on competition math, another on agentic coding, a third on multilingual work, and open models win on cost. The usual response is to pick one and absorb its weak spots. Sakana AI's bet is the other one: don't pick a model — orchestrate a pool of them, and make the orchestration itself the model.
That product is Sakana Fugu (and a heavier tier, Fugu Ultra), shipped behind a single API. Underneath are two ICLR 2026 papers that attack the same problem from opposite ends: TRINITY evolves a tiny coordinator over frozen models, and the Conductor reinforcement-learns a 7B model to write orchestration plans in natural language. This is a walk through both, and what they add up to.
A multi-agent system as a model
Fugu's framing is the whole pitch: one OpenAI-compatible endpoint. You send a
request to model: fugu; behind it a learned coordinator assembles a team from a
pool of frontier and open models, runs them over several turns, and returns one
answer. You never see the routing.
Base Fugu favours a lean, low-latency subset for everyday tasks. Opt a model out for compliance and the coordinator simply routes around it.
The pool is swappable — you can opt a model out for compliance and the coordinator routes around it — and billing is a single top-tier rate rather than stacked per-model fees. There's even an export-controls angle: because Fugu can hit frontier-level quality by coordinating open and semi-open models, you get the capability without hard dependence on any one restricted vendor.
But the API is the boring part. The interesting part is that the coordinator is learned, not hand-written. There are two ways to learn it.
TRINITY: evolve a tiny coordinator
TRINITY's constraint shapes everything: you cannot fine-tune GPT-5's weights, and merging models with incompatible architectures doesn't work. So freeze every model in the pool, and learn only a tiny thing on top that decides who does what.
The coordinator is under 20,000 parameters
A small model — Qwen3-0.6B — reads the current problem state and produces a hidden vector; a linear head turns that into a choice of agent and role. Given the penultimate-token hidden state from the small model, a head of roughly 10K parameters emits logits over agents plus 3 roles, and the coordinator samples its action from
where is the running transcript, are the three roles below, and is everything that gets trained. On top of the head, TRINITY adds singular-value fine-tuning: take an SVD of one or two of the small model's weight matrices and learn only the singular-value scales, keeping the orthogonal factors fixed. That's a few thousand more numbers. Total trainable: under 20K parameters. The 0.6B backbone and all seven frontier and open models stay frozen.
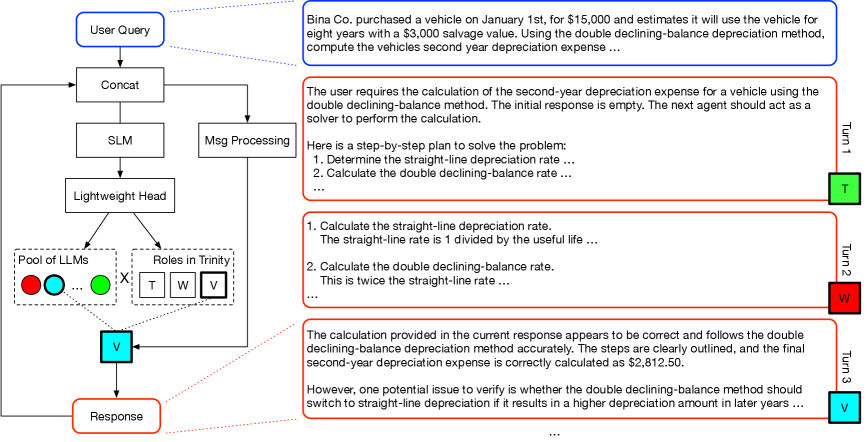
Three roles, looped until accepted
Each turn, the coordinator gives the chosen agent one of three roles:
- Thinker — plan, decompose, or critique; no direct work.
- Worker — do the work: derive, compute, write code.
- Verifier — check the current answer and return
ACCEPTorREVISE.
It loops, accumulating a transcript, and halts the moment a Verifier accepts (or a fixed turn budget is exhausted):
where is the role at turn and is the verifier's verdict. Step through one problem — watch a wrong answer get caught and revised before it's accepted:
Decompose: straight-line depreciation = (cost − salvage) / life. Read off cost = 50000, salvage = 5000, life = 8.
Trained by evolution, not gradients
Why not just RL the head? Because the reward is binary — the final answer is right or wrong — and the head is tiny, so the per-parameter gradient signal is buried in noise. TRINITY instead optimizes the coordinator with a derivative-free evolution strategy, maximizing expected terminal reward:
The optimizer is separable CMA-ES: it keeps a diagonal Gaussian over the ~10K parameters, samples a small population each generation — for — evaluates each candidate's fitness by actually running rollouts, and shifts the distribution toward the winners. The paper shows the coordination objective is nearly block-separable, which is exactly the regime where a diagonal evolution strategy beats both random search and gradient RL under a tight evaluation budget. The honest cost: no gradients means you pay in environment evaluations, and each one is a full multi-turn rollout against real model APIs.
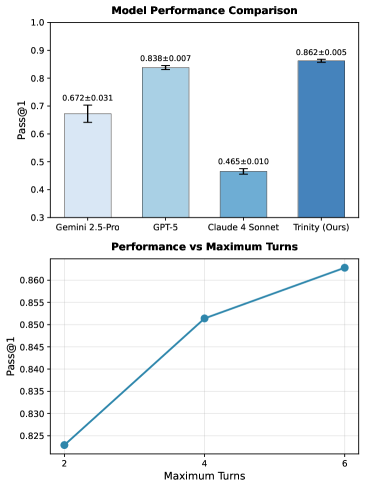
It beats every model in its pool
This is the result that matters. Transferred zero-shot to four held-out tasks, the evolved coordinator outscored every individual model in its pool — including GPT-5, Gemini-2.5-Pro, and Claude-4-Sonnet. On LiveCodeBench it set a record at the time of submission:
And the multi-turn loop earns its keep: accuracy climbs from 0.823 at two turns to 0.863 at six. One cheap evolved head, a frozen pool, and the ensemble beats its best member.
Conductor: orchestration written in natural language
The Conductor attacks the same problem with a bigger hammer: a 7B model (Qwen2.5-7B) trained with RL to write the entire workflow itself, in natural language.
Three lists are a workflow
For each problem the Conductor emits three synchronized lists:
model_id— which agent runs each step.subtasks— a natural-language instruction for each step.access_list— which earlier outputs each step is allowed to read.
Those three lists are a directed graph. The access_list is the load-bearing
idea: [] means the step sees only the original question, ["all"] means it sees
everything produced so far, and [0, 2] means it sees steps 0 and 2. By choosing
access lists, the Conductor designs the communication topology — a chain, parallel
branches, a verify-and-merge — per problem, not from a fixed template. Flip between
the topologies it learns to produce:
Two solvers run from the same setup, then a verifier with access "all" sees every prior output and merges them. The Conductor designs this branch-and-join itself — no human topology.
Trained with GRPO
The Conductor is trained end-to-end with GRPO. For each question it samples a group of candidate workflows, scores each, and pushes the policy toward the above-average ones using the group-normalized advantage
The reward is blunt on purpose: if the three lists don't parse, if the final workflow output is correct, and otherwise — with no KL penalty (). The whole thing trains on just 960 problems for 200 iterations on two H100s. To make one Conductor work over any pool, they then fine-tune it with randomly sampled -model subsets per question, so it adapts to whatever agents you hand it.
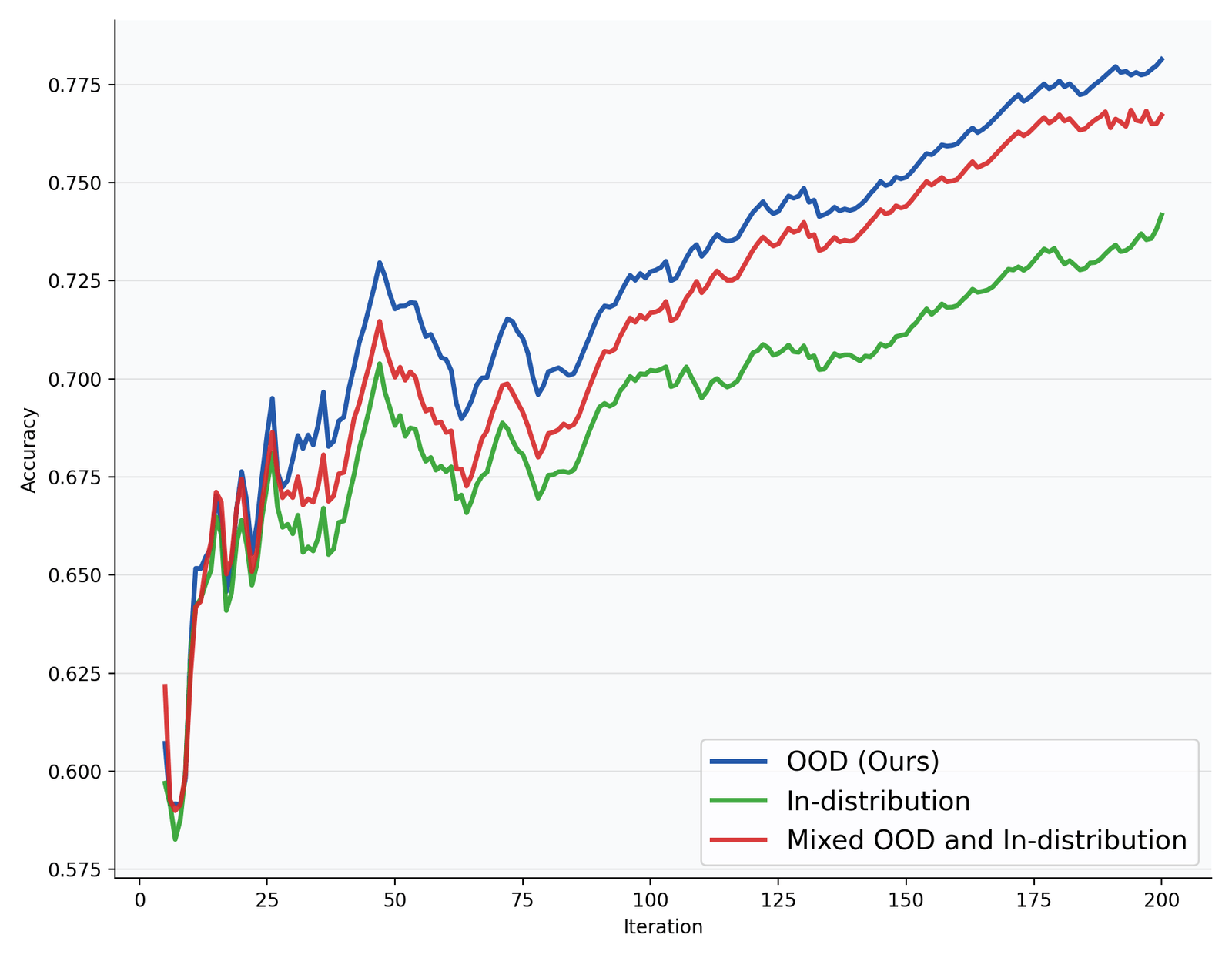
It can call itself
The Conductor may name itself as a worker. That spawns a fresh sub-workflow on its own draft — a recursive topology that turns inference depth into a tunable compute axis, what Sakana calls dynamic test-time scaling. Recursion buys a point or two on the hardest benchmarks for under 2× the agent calls.
Results
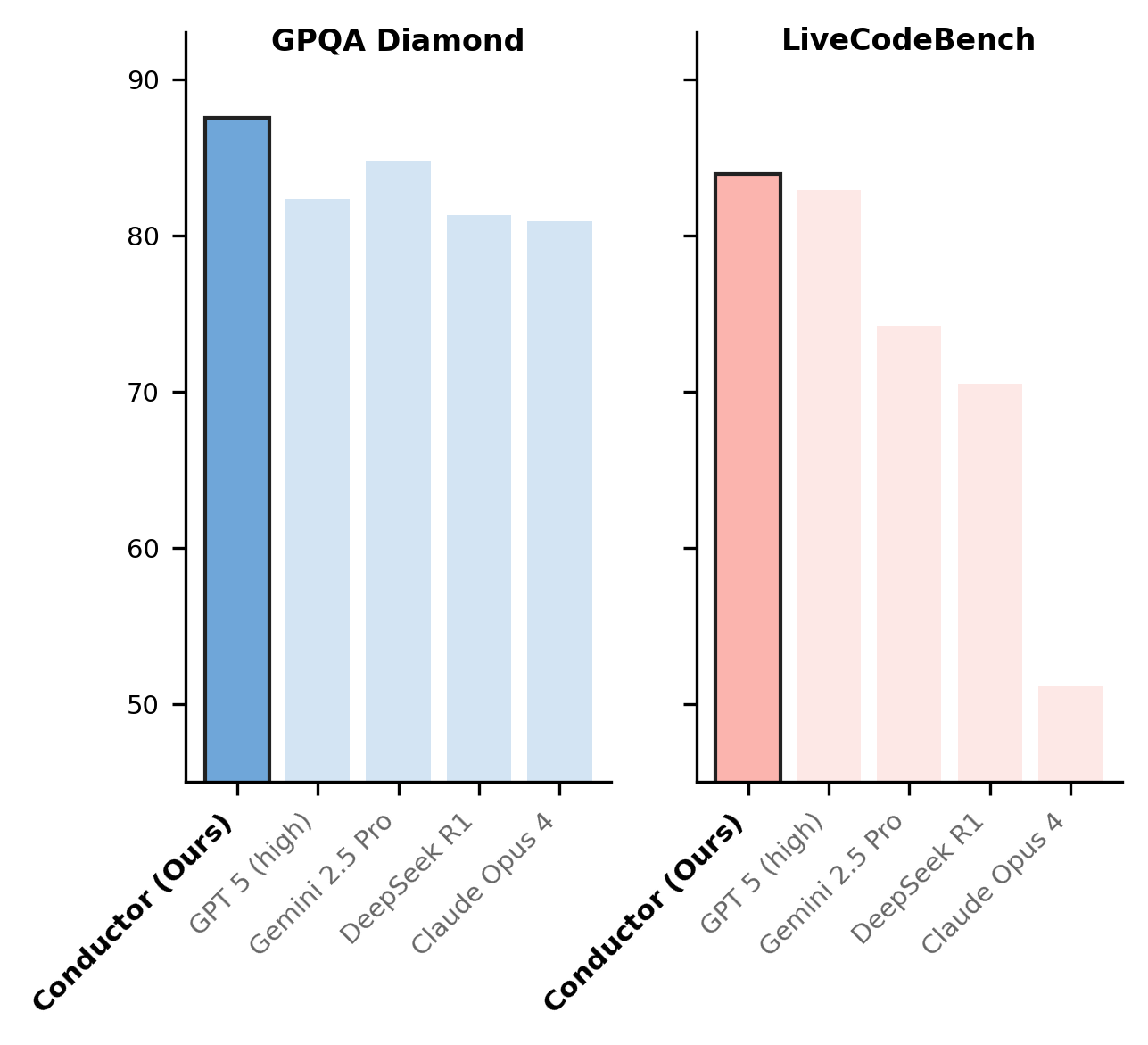
A 7B model orchestrating frontier workers beats the frontier workers. In a controlled run over the same pool:
Unconstrained, the headline numbers were each a new high at publication and each above the best single worker: 83.9% on LiveCodeBench, 87.5% on GPQA-Diamond, 93.3% on AIME25 — reached with about 3 agent calls per question, versus 5–8 for prior multi-agent methods.
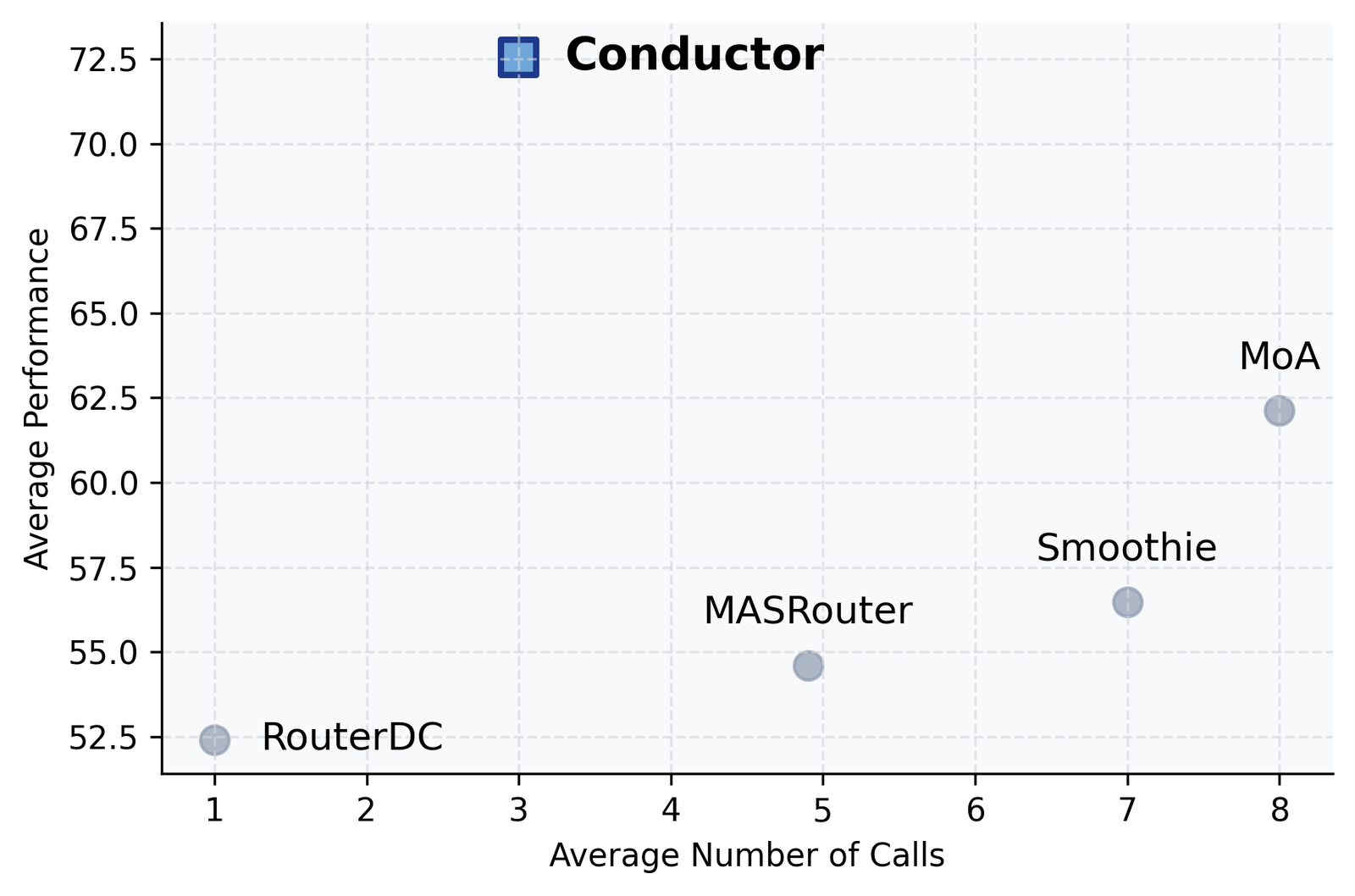
Two routes to the same place
TRINITY and the Conductor are the same idea — a learned layer that coordinates a pool — built at opposite scales:
| TRINITY | Conductor | |
|---|---|---|
| Learnable size | < 20K params (evolved head) | 7B params (RL-trained model) |
| Training | derivative-free sep-CMA-ES | GRPO (reinforcement learning) |
| Output per step | (agent, role) | a full natural-language workflow |
| Coordination | fixed Thinker/Worker/Verifier loop | a topology it designs per problem |
| Reads the task via | the small model's hidden state | reasoning in language |
| Adapts to new pools | re-evolve (cheap) | randomized-pool fine-tune |
TRINITY is the minimal, almost-free coordinator; the Conductor is the expressive one that designs bespoke pipelines. Fugu uses both as its engine.
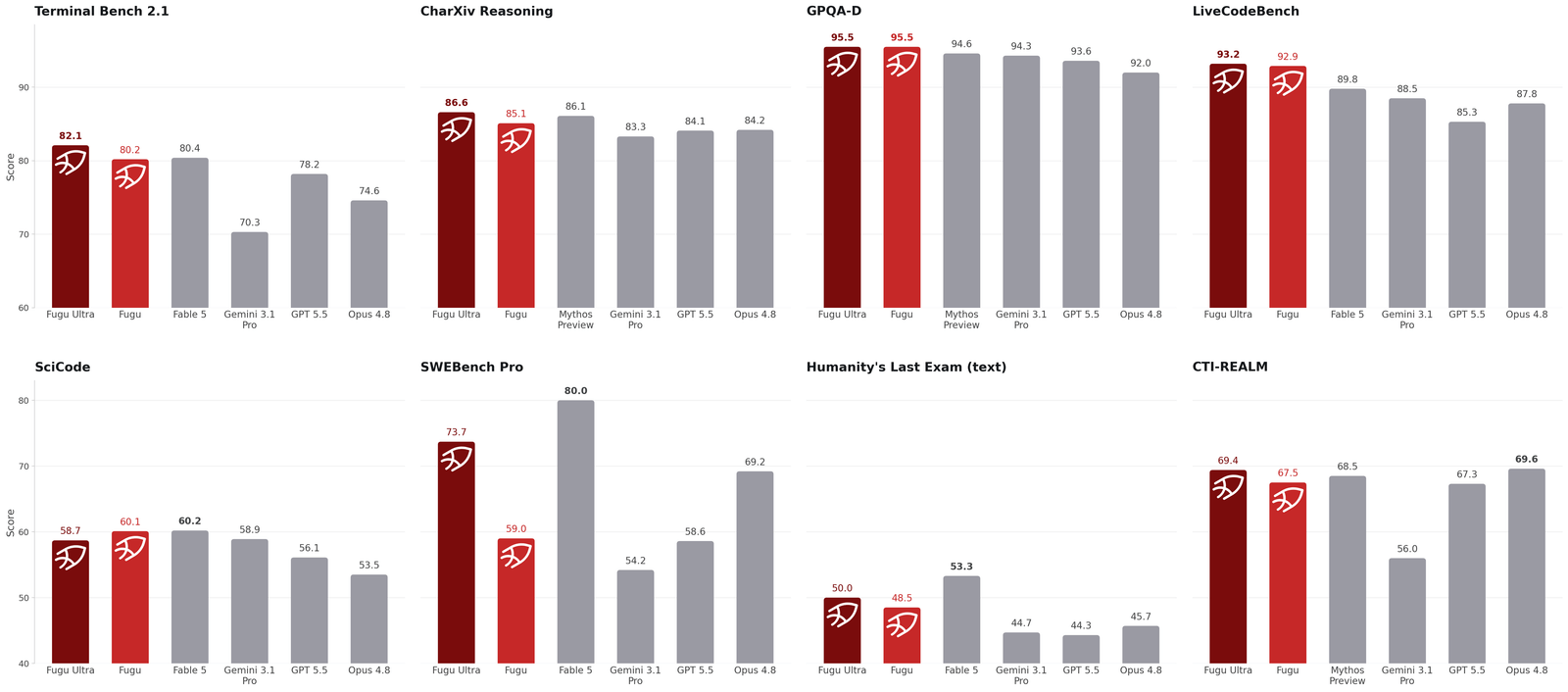
What ships: Fugu and Fugu Ultra
Two tiers. Base Fugu balances quality and latency over a lean pool. Fugu Ultra coordinates a deeper pool over more turns for hard, high-stakes problems, and takes longer for it. On Sakana's reported numbers, both match or beat the frontier:
Fugu Ultra also posts 50.0 on Humanity's Last Exam, against baselines in the 41–50 range. It's an OpenAI-compatible endpoint — change the base URL and key, no SDK migration — and it bills at a single top-tier rate. (Not available in the EU yet, pending GDPR; the exact routing decisions are kept proprietary.)
What I make of it
The honest read:
- The win is real. An orchestration layer that beats every model it coordinates — and generalizes zero-shot to unseen tasks — is a genuine result. "Coordination" is now a trainable layer that sits above frontier models rather than inside one.
- The costs are real too. Every model in the pool has to be available at inference; you trade single-model simplicity for a fleet, and latency rises with the extra turns. The biggest gains concentrate on long-tail reasoning and coding benchmarks — on easy tasks the lift is small — and leaning on GPT-5/Claude/Gemini as workers inherits their cost.
- The framing is the interesting part. TRINITY argues the coordinator can be almost free: 20K evolved parameters over frozen models. The Conductor argues coordination is itself a reasoning skill worth a 7B model and a full RL run. Both point the same way — as individual models plateau, the next axis is how you make several of them work together, and that orchestration is learnable.
Built on Sakana AI's TRINITY: An Evolved LLM Coordinator and Learning to Orchestrate Agents in Natural Language with the Conductor, both ICLR 2026. Product: Sakana Fugu.