2026-06-27 · 11 min · llm · multi-agent · mixture-of-agents · nous-research · open-weights · explainer
"Hermes MoA" isn't one thing, so let me separate the threads before building anything, because the difference between them is the difference between a real result and a marketing claim.
- Mixture-of-Agents (MoA) is a real, well-cited technique from Together AI / Duke / Stanford — arXiv:2406.04692. It's the foundation everyone means by "MoA".
- Nous Hermes is a real open-weight model family. The current Hermes 4 (14B / 70B / 405B) is a single hybrid-reasoning model — it does not itself use MoA.
- The genuine bridge between them is Nous's Forge Reasoning API (Nov 2024), which really did run MoA — plus Monte Carlo Tree Search and Chain of Code — on top of Hermes 70B.
- There is also a body of 2026 "Hermes Agent MoA" claims that I'll get to at the end, and explicitly flag as unverified.
So the honest construction is: here's the MoA mechanism, here's the open-weight Hermes line and why it's a natural host for it, and here's how Nous actually shipped the two together. Let's build it.
The core idea: proposers and aggregators
A single LLM gets one shot at your prompt. MoA's bet is that several models, allowed to read each other's drafts and synthesize, beat any one of them — even when the individual drafts are mediocre.
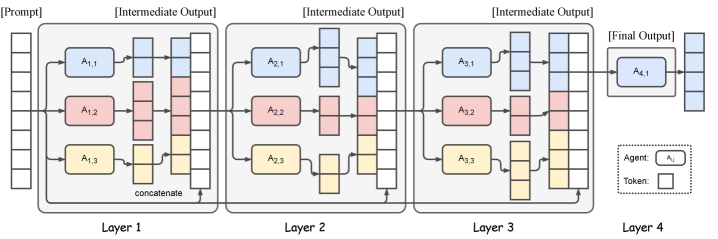
The structure is a stack of L layers, each with n agents. Agents play two roles:
- Proposers generate candidate responses. Diversity matters more here than any single proposer's quality — you want different mistakes, not the same answer four times.
- Aggregators take the candidates and synthesize a single, better response.
The data flow is the load-bearing part: every agent in layer receives all outputs from layer , concatenated into an Aggregate-and-Synthesize prompt that tells the model to critically evaluate the candidates and fuse them. The final layer's aggregator emits the answer. Watch one round play out — four diverse proposers, each right about a different piece, fused into an answer that beats all of them:
…
…
…
…
…
The synthesized answer (71%) clears the best single proposer (64%) because each draft contributed a different correct piece — the mechanism, the law, the number, the perception caveat. That lift from fusing diverse, individually-incomplete drafts is collaborativeness.
Stack that into layers and the synthesized answer sharpens further. Add depth and watch the quality climb:
The Kuiper Belt is past Neptune. It has icy bodies. Pluto is one of them.
One model, one pass — fluent but thin, and it drops the scattered disc entirely.
Why conferring helps: collaborativeness
The empirical observation that motivates the whole thing: an LLM produces a better answer when shown other models' responses — even when those responses are individually weaker than what it would have written alone. The paper calls this collaborativeness, and it's the reason MoA isn't just "best-of-n with extra steps".
The mechanism is concrete. The aggregator isn't voting; it's reading. A proposer that nailed the units, another that caught an edge case, a third that structured the explanation — the aggregate-and-synthesize prompt lets one model keep the part each proposer got right and drop the rest.
What MoA scores
The headline result is that a stack of open-source models, conferring, beats a single frontier model. On AlpacaEval 2.0 (length-controlled win rate):
Open-only MoA hits 65.1% against GPT-4 Omni's 57.5% — a +7.6-point margin with no closed model in the loop. On MT-Bench it scores 9.25 (9.40 with GPT-4o added) versus GPT-4 Omni's 9.19, and on FLASK it leads on robustness, correctness, factuality, and completeness against the strongest single proposer.
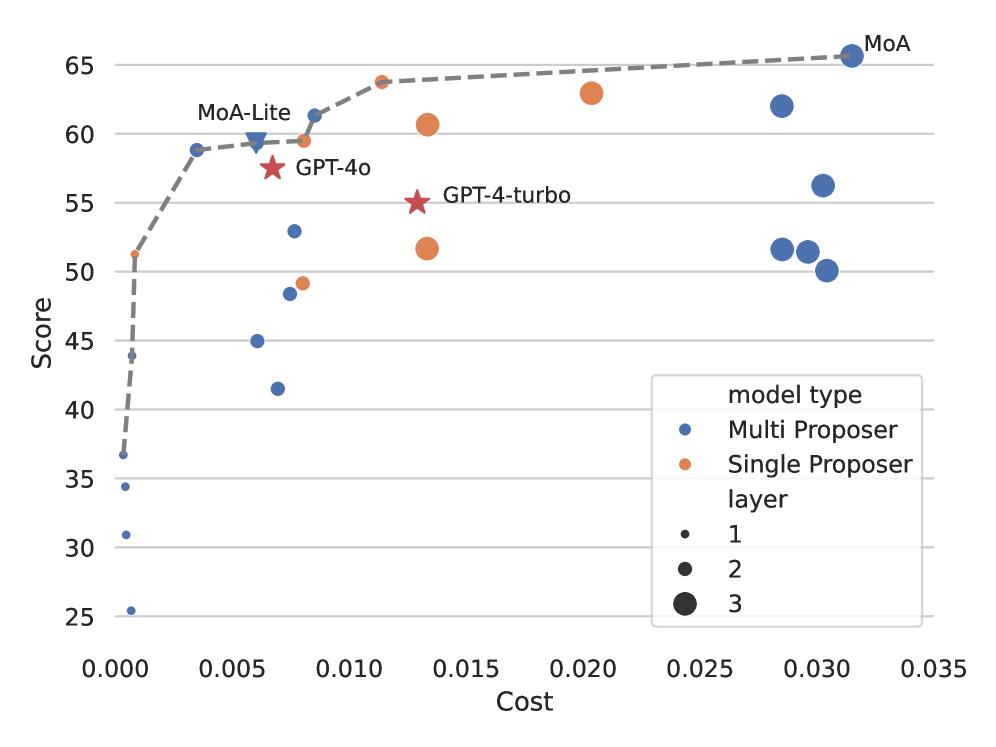
The cost is exactly what you'd expect: proposers across layers means many model calls per answer, and latency stacks with depth. MoA buys quality with compute. Whether that trade is worth it depends entirely on how much you value the marginal correctness.
A shallow, wide stack captures most of the gain cheaply: a couple of layers and a handful of diverse proposers. Quality saturates fast, so more depth mostly costs latency.
Design choices that actually move the needle
MoA has three knobs, and they don't all behave the way intuition says:
- Width (proposers) over depth (layers). The bulk of the gain comes from having several diverse proposers in the first layer; stacking more layers helps less and costs latency linearly. The toy above saturates fast in for exactly this reason.
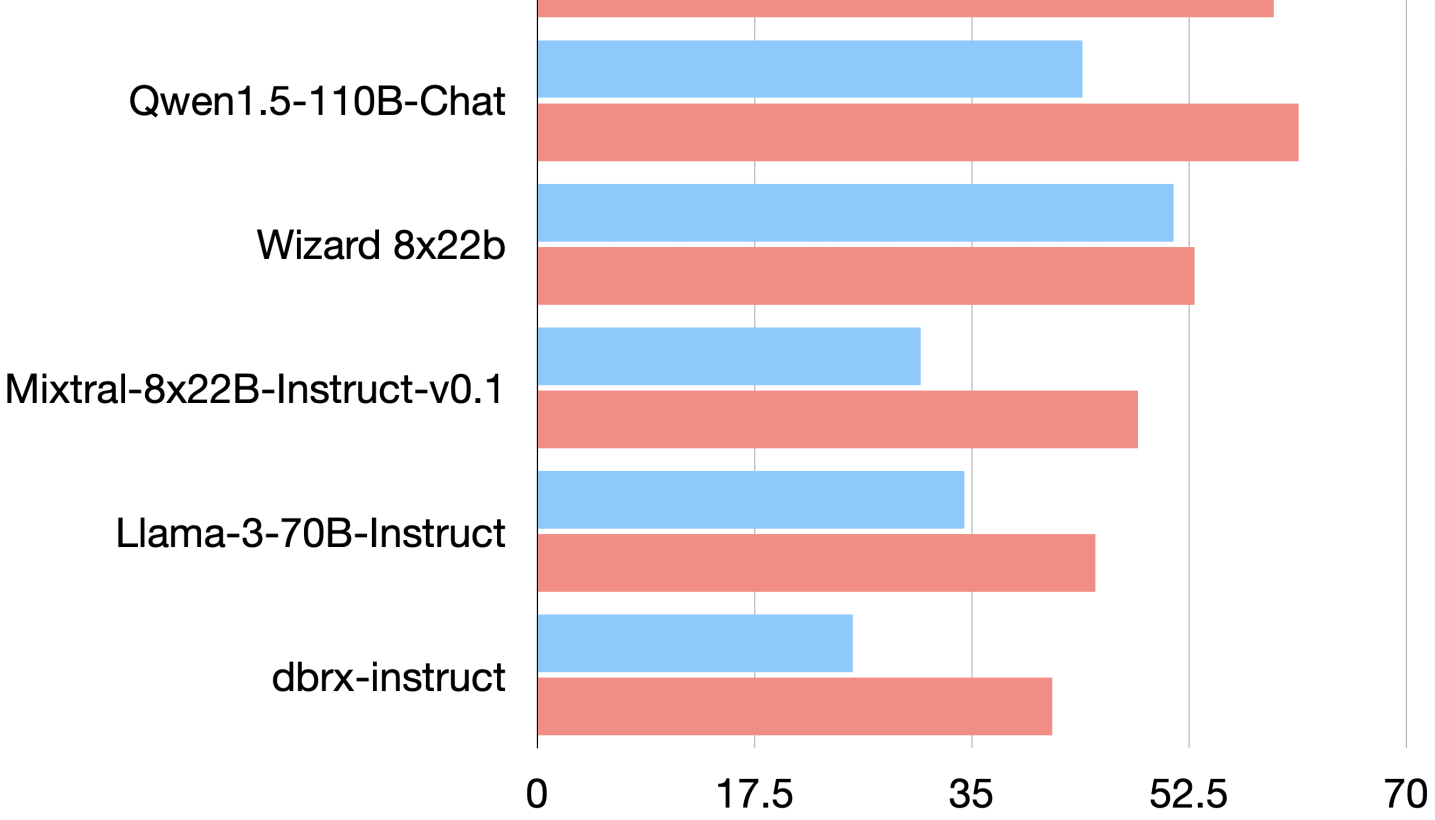
- Diversity beats raw strength. Proposers that fail differently give the aggregator more to work with than several copies of the strongest model. The paper's pool is deliberately heterogeneous — Qwen, WizardLM, Llama-3, Mixtral, dbrx — not six clones.
- The aggregator is a real choice. Not every strong model is a good synthesizer; the aggregator has to read several candidate answers and fuse them faithfully rather than just re-emit its own. The paper uses Qwen1.5-110B-Chat as the final aggregator, and the role-suitability of a model as aggregator vs proposer is measured separately.
You can see the effect dimension-by-dimension on FLASK, which scores along twelve skill axes rather than one number:
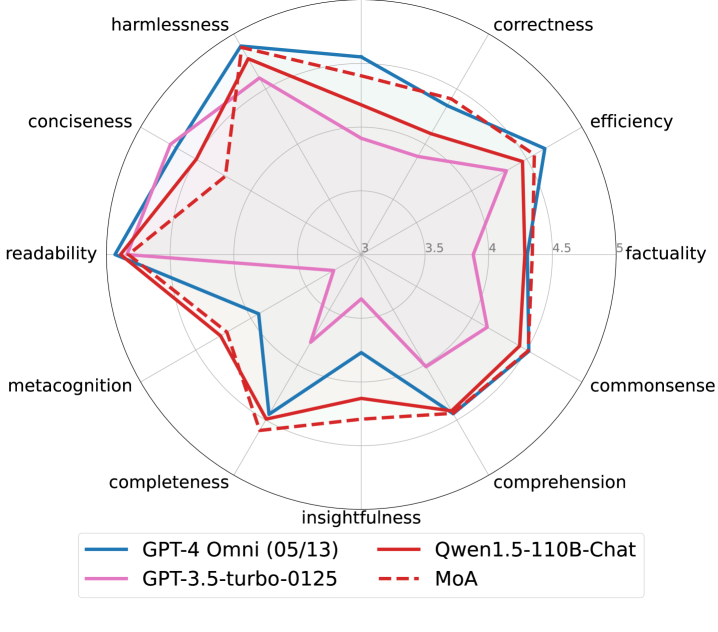
The shape of that result is the tell: MoA helps exactly where having several independent attempts to cross-check is valuable, and barely moves dimensions that a single competent model already nails.
Where Hermes comes in
Nous Research builds the Hermes line — open-weight models post-trained with a
deliberate neutral alignment philosophy: minimal gratuitous refusals, maximal user
steerability. Hermes 4 (70B and 405B on Llama-3.1 bases, 14B on a Qwen3 base) adds
hybrid reasoning — a single checkpoint with a toggleable <think>…</think> block,
so you get reasoning and instruct behavior from one model — plus strong function
calling and JSON-schema structured output. It was trained on ~60B tokens (~5M samples)
built with Nous's DataForge and the Atropos RL environment, rejection-sampled against
roughly a thousand task-specific verifiers, on 192× B200 GPUs.
On capability it's competitive with the open frontier (Hermes 4 405B, reasoning mode):
| Benchmark | Hermes 4 405B (reasoning) | non-reasoning |
|---|---|---|
| MATH-500 | 96.3 | 73.8 |
| AIME'24 | 81.9 | 11.4 |
| AIME'25 | 78.1 | 10.6 |
| GPQA Diamond | 70.5 | 39.4 |
| LiveCodeBench v6 | 61.3 | 28.1 |
| MMLU | 87.2 | 73.6 |
But the number that captures the philosophy is RefusalBench — Nous's own measure of how often a model refuses across 32 categories of typically-refused requests (higher = fewer refusals, except for a few inverted safety categories scored the other way):
That steerability is what makes Hermes a natural MoA citizen. Open weights mean you can run a whole proposer pool yourself; neutral alignment means the aggregator won't refuse to synthesize half its inputs. Hermes is built to be driven, which is exactly what a multi-agent harness does to it.
The real bridge: Forge
The genuine "Nous ran MoA on Hermes" artifact is the Forge Reasoning API (beta, Nov 2024). Forge combined three inference-time techniques on top of Hermes 70B: Mixture-of-Agents, Monte Carlo Tree Search, and Chain of Code. The MoA piece is exactly the mechanism above — "models respond, confer, and synthesize new answers" — applied to a Hermes-centric pool. If you want a concrete instance of MoA on the Hermes line that actually shipped, Forge is it.
Forge stacked three inference-time techniques that compose cleanly because they attack different failure modes:
- Mixture-of-Agents — breadth. Several models propose and an aggregator synthesizes, the mechanism above.
- Monte Carlo Tree Search — depth. Instead of one greedy chain, explore a tree of reasoning continuations and back up value estimates, spending more search on promising branches. This is the "think longer on hard problems" axis.
- Chain of Code — grounding. Offload the steps that are better executed than reasoned about (arithmetic, string manipulation, logic) into code that actually runs, so the model isn't bluffing its way through a calculation.
Breadth, depth, and grounding are orthogonal, which is why bolting all three onto a fixed Hermes backbone bought more than any one alone.
A practical MoA instantiation Nous-style also collapses the textbook diagram into something cheap: a small reference model runs first without tool schemas (avoiding refusals and saving tokens), its output is appended as private context, and the aggregator — the real Hermes agent — does the actual tool-calling loop with the reference draft in hand. One layer, two roles, most of the benefit. It's a reminder that "MoA" in production rarely looks like the 3×6 textbook diagram; it's whatever proposer/aggregator split pays for itself.
What I make of it
- The result is real and a little counterintuitive. Open models that read each other's drafts beat a single frontier model on AlpacaEval, and the lift comes from collaborativeness — synthesis from diverse, even weaker, drafts. That's a genuine, reproducible finding with public code.
- Hermes is the right host, not the inventor. MoA is Together AI's; Hermes is Nous's open-weight, neutral-alignment line; Forge is where Nous actually combined them. Keep the attribution straight and the story is clean.
- The cost is the catch, as always. model calls per answer and latency that grows with depth. MoA is for when correctness is worth real compute — agentic pipelines, hard reasoning — not for chat you need back in 200ms.
- Be skeptical of the 2026 leaderboard claims. The mechanism is sound; the benchmark numbers floating around are not yet something I'd cite.
Built on Together AI's Mixture-of-Agents Enhances Large Language Model Capabilities (Wang et al., 2024; code), the Hermes 4 Technical Report (Nous Research, 2025), and Nous's Forge Reasoning API.