2026-06-27 · 9 min · llm · multi-token-prediction · inference-optimization · speculative-decoding · explainer
Standard language models are trained on a deceptively narrow task: given everything so far, predict the single next token. The objective is one cross-entropy term per position,
Multi-token prediction (MTP) changes one thing: from each position, predict the next tokens at once. That small change buys two unrelated-looking wins — a model that trains better, and a model that decodes faster — and the second one is why it's now in shipping products from DeepSeek to Google.
A provenance note up front, because the "Google multi-token prediction" framing gets the credit wrong. The modern MTP training objective was defined by Meta (FAIR) in Gloeckle et al., 2024. The predict-several-then- verify decoding idea it reuses traces to Google Brain's 2018 blockwise parallel decoding. DeepSeek-V3 productionized a sequential variant at pretraining scale. And Google's genuine 2026 contribution is applied: MTP-based speculative decoding in Gemma 4 and on-device Gemini Nano. I'll attribute as I go.
The objective: predict n futures
Keep one shared transformer trunk that turns the context into a latent . Attach output heads. The loss sums cross-entropy over the next positions:
From position , head predicts . Pick and a flavor and read the loss off directly:
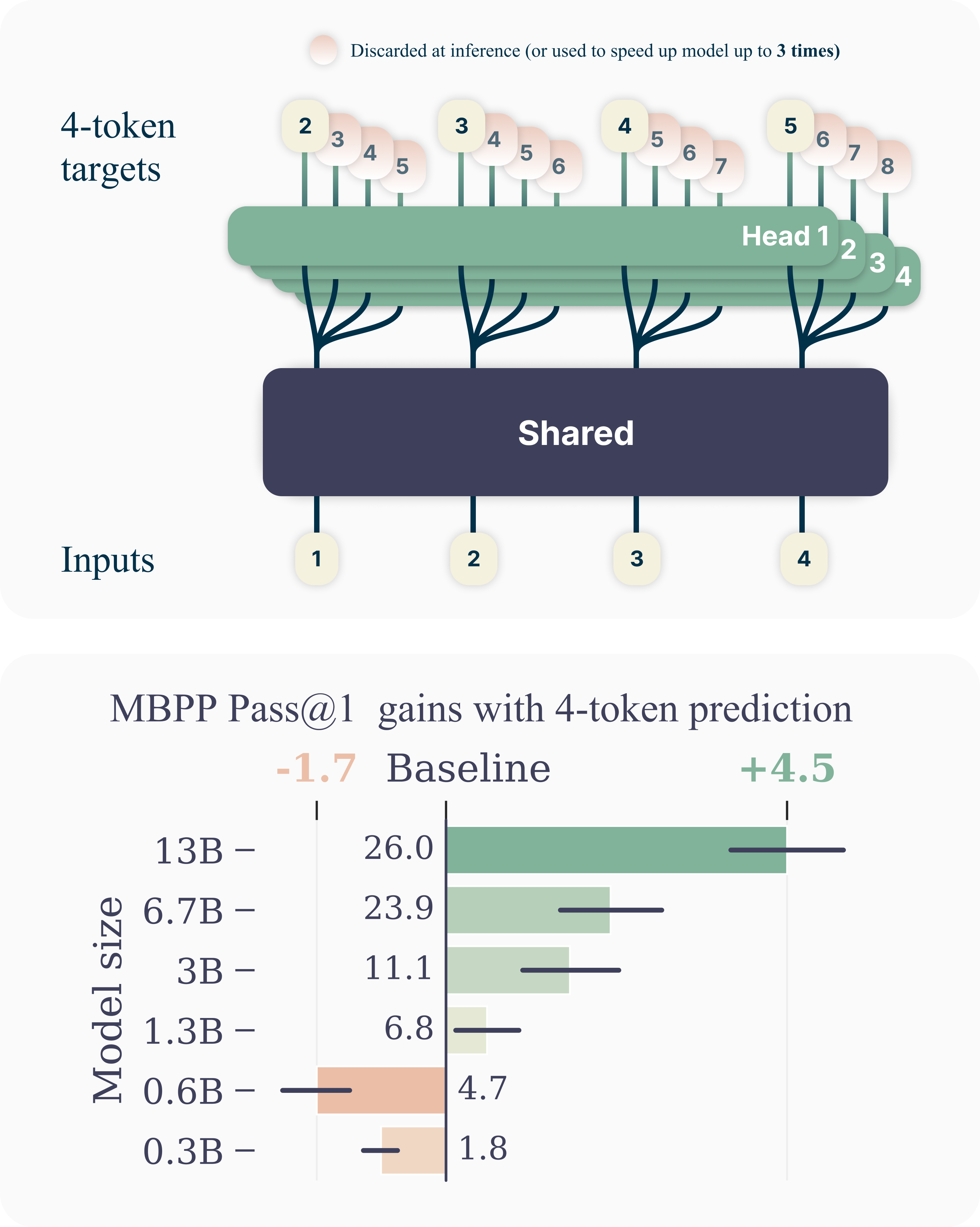
Meta's heads are independent off the same trunk — they don't see each other's predictions. Cheaper, and at inference you can discard the extra heads for a zero-overhead next-token model, or keep them to self-speculate.
The obvious worry is memory: materializing full vocabulary-sized logit tensors at once is brutal. The fix is mundane and important — compute each head's forward/backward sequentially and accumulate gradients at the trunk, so peak memory stays flat in . You pay a little time, not a lot of VRAM.
Two flavors: parallel heads vs sequential modules
The flavor toggle above is the real architectural fork.
- Meta / Medusa — parallel independent heads. All heads hang off the same trunk and predict in parallel; head 2 does not see head 1's token. Cheap, and it composes with a clean inference trick: at deployment you can discard the extra heads and recover an ordinary next-token model with zero overhead, or keep them to self-speculate.
- DeepSeek-V3 — sequential modules that keep the causal chain. Module takes the previous depth's hidden state, concatenates the embedding of the (already-known) token, RMS-norms both, projects, and runs its own transformer block. So depth-2's prediction is conditioned on depth-1's token — the drafts are internally coherent, at more cost than parallel heads.
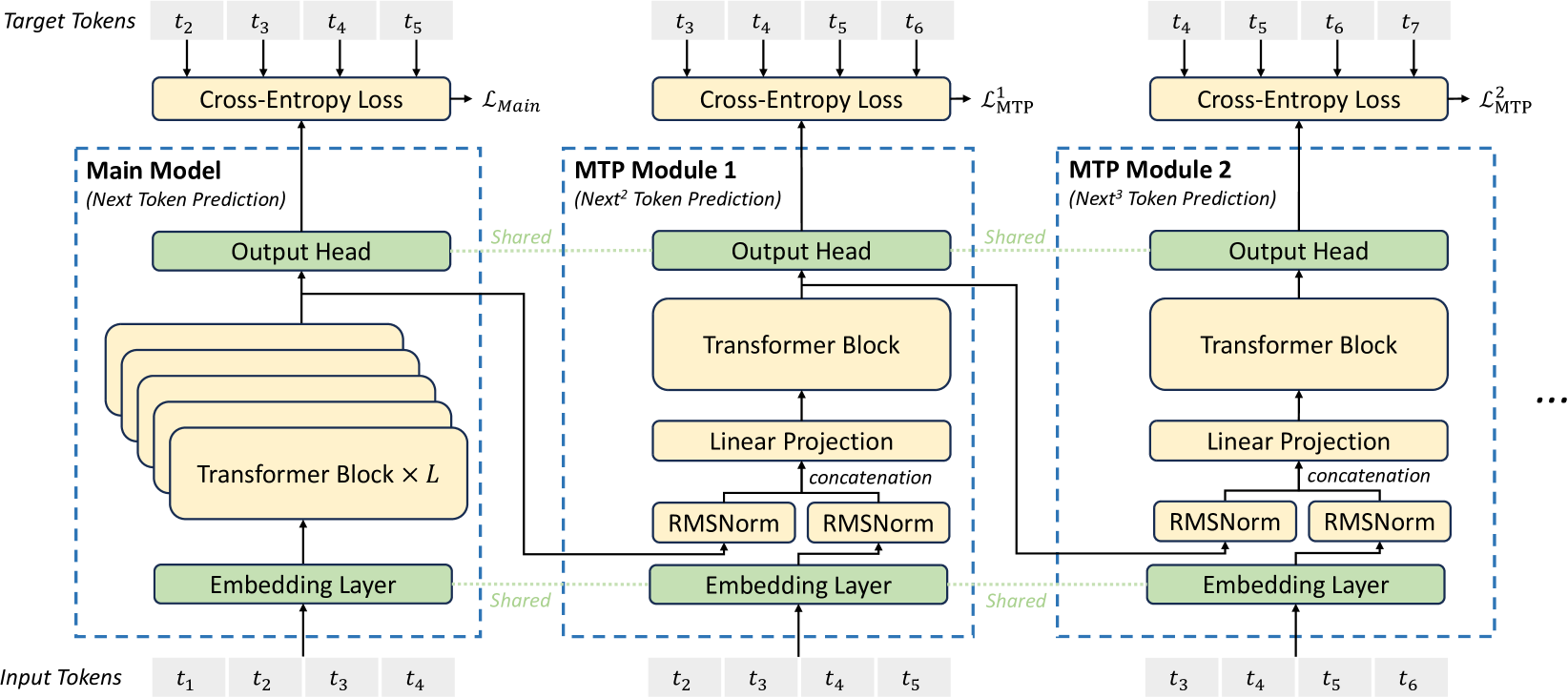
The trade is exactly what you'd guess: parallel heads are cheaper and discardable; sequential modules draft more coherent blocks because each step sees the last.
Win one: it trains a better model
The training objective is the whole reason for the quality gain. Slide the window: from each position the model predicts the next tokens, so loss terms fire where an ordinary model gets one. Flip between 1 and 4 to feel the supervision get denser:
At n=4 each position supplies 4 loss terms, forcing the trunk to encode information about tokens further ahead — a denser signal that, at scale, yields a better model even after the extra heads are thrown away.
Predicting further is a denser, more demanding signal, and at scale it produces a model that's better even when you throw the extra heads away. Meta's 13B model, trained with MTP, solves materially more coding problems than the matched next-token model on the same data and compute:
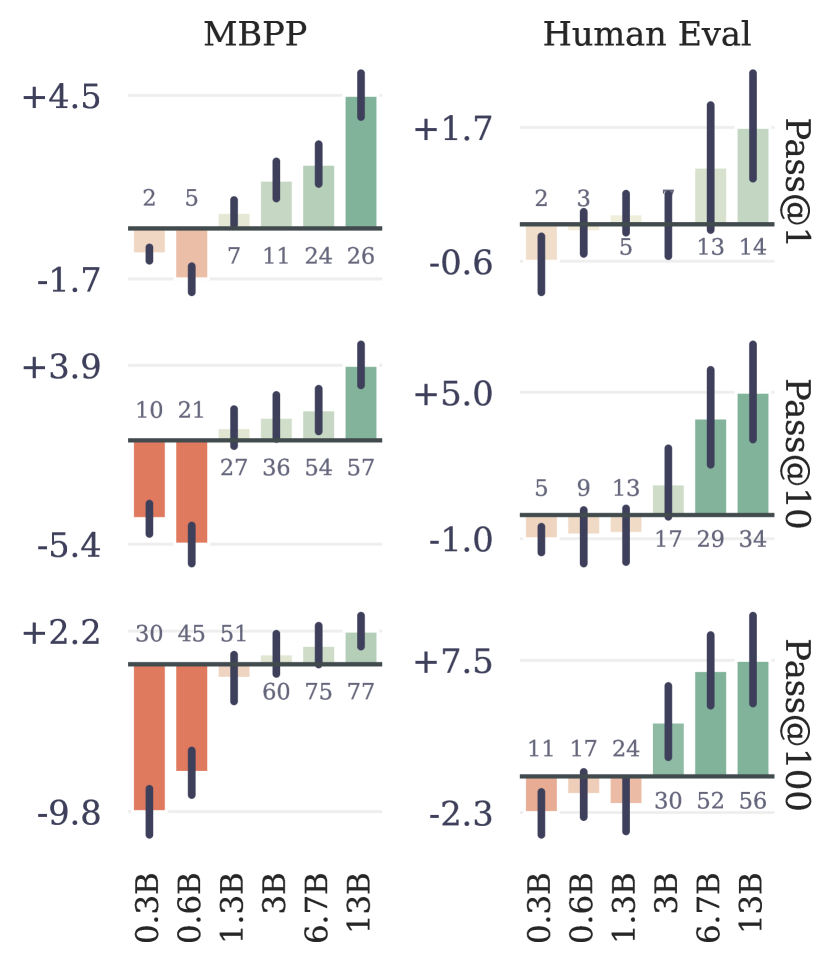
Two caveats keep this honest. The gains scale with model size — small models barely benefit, and very large erodes quality ( is the sweet spot for ~7B on code). And whether the quality gain transfers beyond pretraining is genuinely contested: "Multi-Token Prediction Needs Registers" (MuToR, NeurIPS 2025) exists precisely because the benefit hasn't consistently generalized to fine-tuning without help. MTP is not a free quality lunch in every regime.
Win two: it decodes ~3x faster
The extra heads are a built-in draft model. They cheaply propose the next tokens in one pass; the model then verifies all of them in a single batched forward and accepts the longest correct prefix — self-speculative decoding. This is lossless: rejected drafts fall back to the true next-token distribution, so output is unchanged.
That verify-and-accept scheme is the part with Google's fingerprints — Stern, Shazeer & Uszkoreit's 2018 blockwise parallel decoding at Google Brain is the ancestor: predict several future positions with auxiliary heads, then accept the longest correct prefix. MTP simply folds those auxiliary heads into the training objective.
How much you gain depends entirely on the acceptance rate — how often a drafted token matches what the target would have produced. Because acceptance compounds along the block, the marginal value of the -th drafted token decays, and the whole scheme hits a ceiling no matter how far you draft. That's why a more coherent drafter is worth more than a longer one — and why DeepSeek's sequential modules (higher acceptance) and DSpark's semi-autoregressive head exist at all. Drag the acceptance rate and block size:
The gain from the i-th drafted token decays like αi, so the curve saturates at 1 + α/(1−α) no matter how long you draft. High acceptance pushes the ceiling up; low acceptance means even n=8 barely beats n=2. That decay is exactly why n≈4 is the practical sweet spot — and why a more coherent drafter (higher α) buys more than a longer one.
The speedups, across the lineage:
DeepSeek-V3 is the cleanest production data point: with MTP depth (predict two tokens total), the second token is accepted 85–90% of the time, and repurposing the module for speculative decoding gives ~1.8× tokens/sec. The training loss weight was annealed — for the first 10T tokens, then for the remaining 4.8T — a detail worth noting because MTP at pretraining is a secondary objective, not the main one.
Google's actual 2026 role: applied MTP
Where Google genuinely shows up is deployment, not the objective:
- Gemma 4 MTP drafters (April 2026): MTP-style draft heads for lossless speculative decoding, with a runtime heuristic that adapts how many tokens to draft. Google's release claims up to ~3x faster inference, no quality loss — present that as a vendor figure; the official docs only say "significant speedups".
- Gemini Nano frozen MTP (June 2026): a frozen-backbone MTP head for on-device speculative decoding on Pixel. It correctly predicts ~2 extra tokens per pass, gives a 50%+ speedup on Pixel 9 over a standalone drafter, lifts token acceptance ~55% on structured text, and — the on-device kicker — costs −130MB per instance by sharing the KV cache zero-copy instead of running a separate draft model.
The on-device framing is the interesting one: a separate draft model is a non-starter when you're counting megabytes on a phone, so folding the drafter into the main model as a frozen head is exactly the right move.
The open questions
MTP isn't a closed book — two recent threads are worth knowing because they bound where the simple story breaks.
- Does the quality gain survive fine-tuning? Meta's gains are a pretraining phenomenon, and they don't reliably transfer when you only have a fine-tuning budget. "Multi-Token Prediction Needs Registers" (MuToR, NeurIPS 2025) addresses this by interleaving learnable register tokens into the sequence, each responsible for predicting a future token — adding almost no parameters and no architectural surgery, so MTP's benefit shows up in the fine-tuning regime where plain MTP heads underdeliver.
- Can you extract more drafts from a model that already exists? Apple's "Your LLM Knows the Future" argues a standard model already encodes multi-token information, and unlocks it with masked-input MTP plus a gated LoRA and a learnable sampler — reporting roughly 5× on code/math and 2.5× on general chat, lossless. The framing is telling: MTP capability may be latent in next-token models, waiting for the right decoding head.
Both reinforce the same lesson the speedup curve shows: the value is in acceptance and coherence, and the active research is about getting more of both without paying a full retrain.
Who did what
| Work | Org | Contribution |
|---|---|---|
| Blockwise parallel decoding (2018) | Google Brain | predict-several-then-verify/accept — the decoding ancestor |
| Better & Faster LLMs via MTP (2024) | Meta / FAIR | the canonical MTP training objective (n parallel heads) |
| Medusa (2024) | academic | multiple decoding heads + tree attention (not Google) |
| DeepSeek-V3 MTP (2024) | DeepSeek-AI | sequential MTP modules at pretraining; ~1.8× TPS |
| MuToR — "MTP needs registers" (2025) | academic | register tokens so MTP helps in fine-tuning |
| Gemma 4 / Gemini Nano MTP (2026) | applied MTP speculative decoding, incl. on-device |
What I make of it
- One change, two payoffs. Predicting futures is a denser training signal and a free draft model. That two-for-one is why MTP spread so fast from a 2024 paper to 2026 phones.
- The flavors matter. Parallel heads are cheap and discardable; sequential modules draft coherent blocks. Pick by whether you care more about training overhead or draft acceptance.
- Keep the credit straight. Meta defined the objective, Google Brain seeded the verify/accept decoding, DeepSeek productionized it, and Google's 2026 work is applied speculative decoding — strongest exactly where a separate draft model can't fit, like on-device.
- Mind the caveats. Quality gains scale with size and don't automatically survive fine-tuning; the headline speedups are real but partly vendor-reported. The lossless speed win is the part to trust unconditionally — it's guaranteed by the acceptance rule, not a benchmark.
Built on Meta's Better & Faster Large Language Models via Multi-token Prediction, the DeepSeek-V3 Technical Report (§2.2), Google Brain's Blockwise Parallel Decoding, MuToR, and Google's 2026 Gemini Nano frozen-MTP work.