2026-06-28 · 8 min · llm · training · systems · cuda · explainer
The thing that stops most people from training a big model isn't FLOPs — it's GPU memory. A 70B model's parameters, gradients, and Adam moments don't fit in an 80GB card, so you reach for tensor/pipeline parallelism across a cluster you may not have, or for offloading systems that thrash and OOM as the model grows.
MegaTrain takes the other path: invert the memory hierarchy. Host CPU memory becomes the authoritative store for all persistent state — parameters, gradients, and optimizer moments — and the GPU is demoted to a transient compute engine that holds only the layer it's working on right now. On a single H200 with 1.5 TB of host RAM, that's enough to train models up to 120B parameters at full precision — no quantization, no second GPU. It's a systems paper, and a good one, so let's read it as systems.
The inversion
Start with the accounting. Mixed-precision Adam costs about 12 bytes per parameter: 2 for the BF16 weight, 2 for the BF16 gradient, and 8 for the FP32 first and second moments. A GPU-centric trainer keeps all of that in HBM, so the moment exceeds the card, you're done. Move that state to host memory and stream one layer at a time, and the device footprint goes flat while the host's terabytes set the ceiling. Drag the model size and watch where it OOMs:
A single H200’s HBM caps a GPU-centric run at roughly 11B parameters. Move the persistent state to the 1.5 TB host and keep only a streamed layer on the device, and the same card trains past 120B— at full precision, no quantization. The catch is what you trade for it: every layer’s weights now cross PCIe twice per step, which is exactly the bottleneck the double-buffered pipeline exists to hide.
That's the whole idea in one slider: a single H200's 141 GB HBM caps a GPU-centric run around 11–12B parameters, but with the persistent state in 1.5 TB of host RAM and only a streamed layer resident, the same card reaches past 120B. The paper's own architecture makes the split concrete — everything lives in the CPU domain; the GPU domain is scratch:
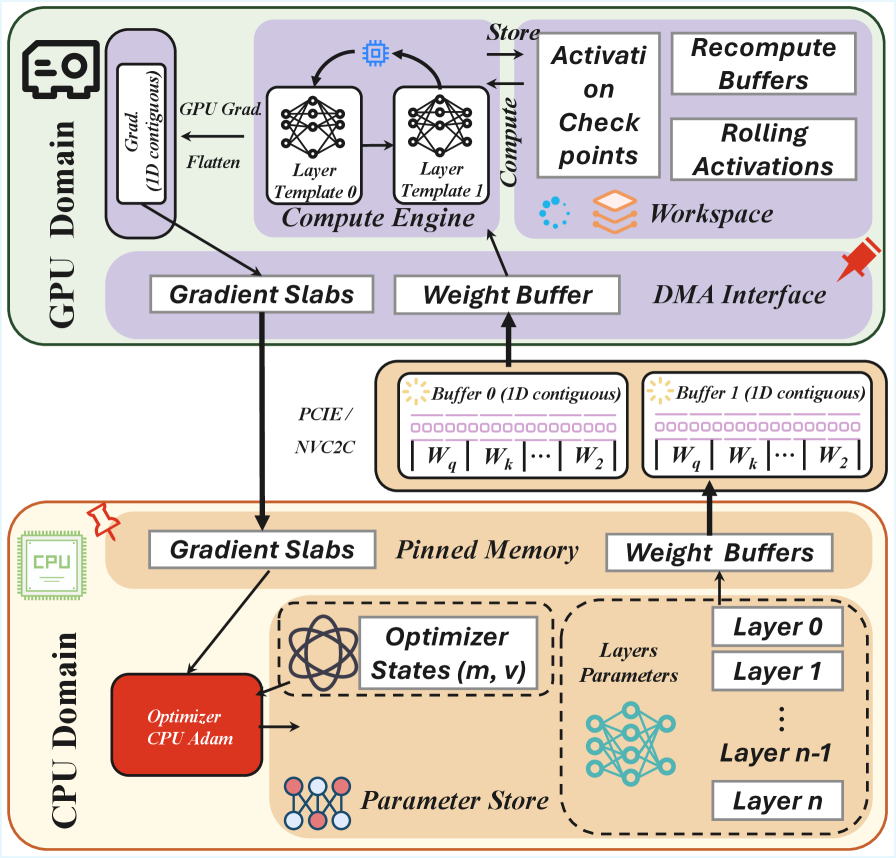
The bottleneck, and the step
Inverting the layout creates one obvious problem: PCIe bandwidth. Every layer's weights now have to cross the bus into the GPU, and its gradients have to cross back — ~128 GB/s on H200's PCIe Gen5, versus 4.8 TB/s of on-card HBM. If you did this naively the GPU would spend most of its life waiting on DMA.
The training step is three phases built to keep that traffic off the critical path:
- Streaming forward — stream each layer's weights in (H2D), compute, checkpoint activations every layers, release the weights immediately.
- Block-wise backward — recompute activations from the nearest checkpoint, stream the layer's weights back in, compute gradients in reverse, offload them (D2H), release.
- Optimizer update — run Adam entirely on the CPU (AVX-512), so the freshly computed gradients and the moments never make another round trip to the device.
Block-wise recomputation bounds activation memory at — independent of total depth — which is what lets depth scale without the activation memory exploding.
The double-buffered pipeline
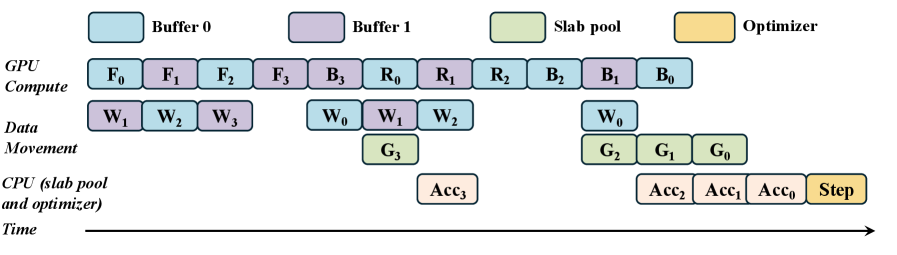
This is the optimization that makes it fast instead of merely possible. MegaTrain runs three CUDA streams concurrently — one for compute, one for H2D weight transfer, one for D2H gradient evacuation — and double-buffers the weights so that while the compute stream works on layer out of one buffer, the next layer's weights prefetch into the other. Flip between naive serialization and the double-buffered schedule:
Double-buffered: while the compute stream chews through layer i, the H2D stream prefetches layer i+1 into the other buffer and the D2H stream drains layer i−1's gradients. The compute lane is gap-free — the GPU never waits on PCIe, and removing this one optimization costs MegaTrain 31% of its throughput.
The coordination is three events — weights-ready, backward-done, buffer-free — and the payoff is a compute lane with no gaps: the GPU never stalls on PCIe. The ablation makes the importance unambiguous. Remove double-buffering and throughput drops 31.3% (266 → 183 TFLOPS at 14B) — by far the largest single contributor, more than the gradient slab pool (−3.3%) or tighter checkpointing. Here's the paper's own timeline of the overlap:
A few more systems details earn their keep:
- Stateless layer templates. A persistent autograd graph assumes weights stay
resident — incompatible with streaming and eviction. MegaTrain uses kernel templates
with no baked-in weight pointers and a
Bindprimitive that maps streamed buffer views into the template's input slots, so device memory never exceeds a single layer. - Layer-contiguous tiling. BF16 weights, BF16 grads, and FP32 moments for a layer are packed into one 4 KB-aligned block, so a layer moves as a single large-burst DMA that saturates PCIe instead of many fragmented transfers.
- Pinned slab pool. A fixed pool of pinned staging slabs (default 12), each sized to the largest layer rather than the whole model, JIT-packed by a CPU worker — you get pinned-memory transfer speed without pinning the entire model.
What it delivers
The headline is a capability, and it's the most convincing part: 120B parameters on one H200, and a 512K-token context on a single GH200. These are regimes where the offload baselines simply OOM — so the comparison is binary, which is the strongest kind.
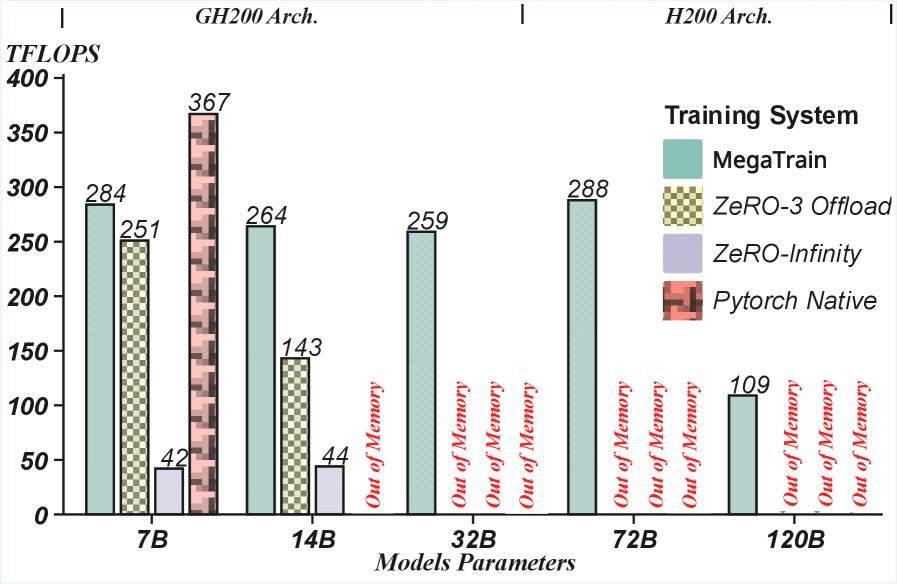
Where the baselines can run but are memory-starved — a 14B model on a PCIe A100 — the margin is large:
That's 8.1× over Gemini and 12.2× over ZeRO-3 — and on a 48 GB A6000 or a 24 GB RTX 3090, MegaTrain trains 14B at all (56.8 and 30.2 TFLOPS) while ZeRO-3 OOMs. Crucially, accuracy doesn't move — full precision means no drift:
| MetaMathQA accuracy | MegaTrain | ZeRO-3 | ZeRO-Infinity | PyTorch |
|---|---|---|---|---|
| 7B | 88.99 | 88.93 | 88.97 | 88.91 |
| 14B | 92.52 | 92.41 | — | — |
On depth, it's the only system that keeps going: ZeRO-3 OOMs by 132 layers and FSDP by 84, while MegaTrain runs the whole range and is 6.14× faster than FSDP at 56 layers. On width, both baselines OOM at 4.0× while MegaTrain alone reaches 5.0×.
What I make of it
- The capability claims are real and well-supported. Training 120B at full precision on one GPU, 512K context on one GH200, and 14B on a 3090 — in each case the baseline cannot run. "Only system that works here" is the most honest result a systems paper can have, and the accuracy-parity table backs the full-precision claim.
- Double-buffering is the load-bearing idea, and the ablation proves it. −31.3% without it is a clean, isolated attribution. The rest — contiguous tiling, stateless templates, CPU Adam — are the supporting cast that make the streaming viable.
- Read the throughput claims with the regime attached. This is single-GPU only — no multi-node scaling, and the metric is TFLOPS, not MFU, which a recomputation-heavy design inflates (you do extra FLOPs re-deriving activations). At small or unconstrained sizes the baselines are actually faster (FSDP 501 vs MegaTrain 406 TFLOPS at 1.0× width); MegaTrain wins specifically once the model is large enough that offload systems are thrashing or out of memory. The 1.84× and 6–12× numbers live near that memory cliff, not everywhere.
- The best numbers lean on expensive hardware. GH200's 900 GB/s NVLink-C2C and H200's 1.5 TB host RAM do a lot of work; on a plain PCIe Gen4 box the absolute throughput is far lower (122 vs 266 TFLOPS). So it democratizes what fits, more than it democratizes speed.
The honest summary: MegaTrain redefines the memory ceiling for single-GPU training — provably, at full precision, with public code — and the double-buffered pipeline is a genuinely nice piece of CUDA-stream engineering. Just don't read "1.84× faster" as a general speedup; read it as "it runs, fast enough, where nothing else runs at all."
Built on MegaTrain: Full Precision Training of 100B+ Parameter Large Language Models on a Single GPU (Yuan et al., 2026; code). All numbers are from the paper's tables and figures.