2026-06-27 · 13 min · llm · inference-optimization · speculative-decoding · deepseek · explainer
The first thing to get straight: DSpark is not a new model. The Hugging Face
cards say it plainly — DeepSeek-V4-Flash-DSpark "is not a new model. It is the
same checkpoint with an additional speculative decoding module attached." DSpark is
an inference accelerator for the existing DeepSeek-V4 weights, shipped alongside an
open training repo called DeepSpec. It
makes generation faster without changing a single output token.
That last clause is the whole reason to care. Speculative decoding is lossless by construction: a cheap draft model proposes a block of tokens, the full target model verifies the whole block in one forward pass, and the acceptance rule keeps exactly the prefix the target would have produced anyway, plus one free "bonus" token. Output is bit-identical to plain decoding. You only buy latency.
So the entire game is the draft-and-verify loop, and DSpark improves both halves of it. Recall the per-token latency of speculative decoding:
where is the accepted length — how many real tokens one expensive target forward bought. You win three ways: draft faster, draft better (raise ), or verify smarter. Prior work chased the first two. DSpark is the first to seriously attack the third.
What's being accelerated: DeepSeek-V4
DSpark exists to serve DeepSeek-V4 — two MoE models, V4-Pro (1.6T params, 49B activated) and V4-Flash (284B, 13B activated), both with 1M-token context. V4 is already aggressively efficiency-engineered: a hybrid of Compressed Sparse Attention and Heavily Compressed Attention, Manifold-Constrained Hyper-Connections (mHC), and the Muon optimizer, trained on >32T tokens.
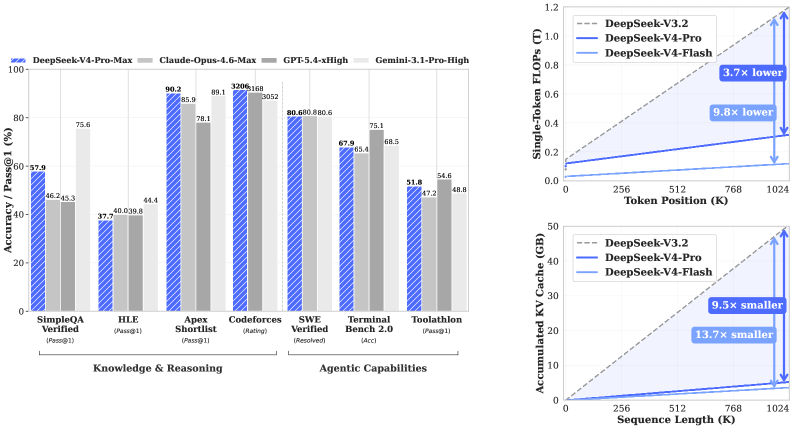
That context matters: when the model itself is this optimized, the decoding loop is where the last big latency wins live, and speculative decoding is the lever. DSpark is the drafter that lever needed.
The loop, one round at a time
First, watch the loop run end to end. The drafter proposes a block (faint), the target verifies it in one forward, the matching prefix locks in and a mismatch is corrected for free — and the meters track the mean accepted length , which is the speedup over vanilla one-token-at-a-time decoding:
Vanilla decoding emits exactly one token per target forward. Speculative decoding emits g— and because the acceptance rule is exact, the text is identical either way. DSpark’s job is to push the mean g up (better drafting) and spend forwards only where they pay off (smarter verification).
Now the same thing in slow motion, one round at a time, so the accept/reject/bonus rule is unambiguous — step through and watch change round to round:
All 5 drafts matched — one expensive target pass produced 6 real tokens instead of 1.
The mismatch case is the one to internalize. When the target disagrees at position , everything after is thrown away — but because the target also tells you its own token at , the round still nets accepted tokens. You never lose ground, and you never change the answer. The only question is how big gets on average.
Why long draft blocks were a trap
Early drafters were autoregressive — each draft token conditions on the previous one (EAGLE-style). Quality is high, but drafting latency grows linearly with block size, so you're forced into short, shallow blocks.
Parallel drafters (DFlash, Medusa) flipped this: produce all draft logits in one forward pass, so drafting latency is nearly independent of block size. In principle you can now draft long blocks cheaply. In practice two things break:
- Quality. Each position is predicted independently, so it can't condition on the tokens actually sampled elsewhere in the block. Given a context with two plausible continuations — "of course" and "no problem" — a parallel drafter happily emits "of problem" or "no course", because each slot marginalizes over all predecessors instead of committing to one. Acceptance decays fast down the block.
- System efficiency. Even when long blocks are good, indiscriminately verifying all of them wastes target-model batch capacity. Under high concurrency that capacity is the bottleneck, and verifying tokens that will be rejected is pure loss.
DSpark's two components map one-to-one onto these two failures.
Component 1: semi-autoregressive drafting
The fix for the quality problem is to put a little sequentiality back, cheaply. A heavy parallel backbone (DeepSeek uses DFlash here) runs one forward pass over the whole block and emits per-position hidden states and base logits. Then a lightweight sequential head runs over those, injecting intra-block dependencies so position can finally see the token sampled at .
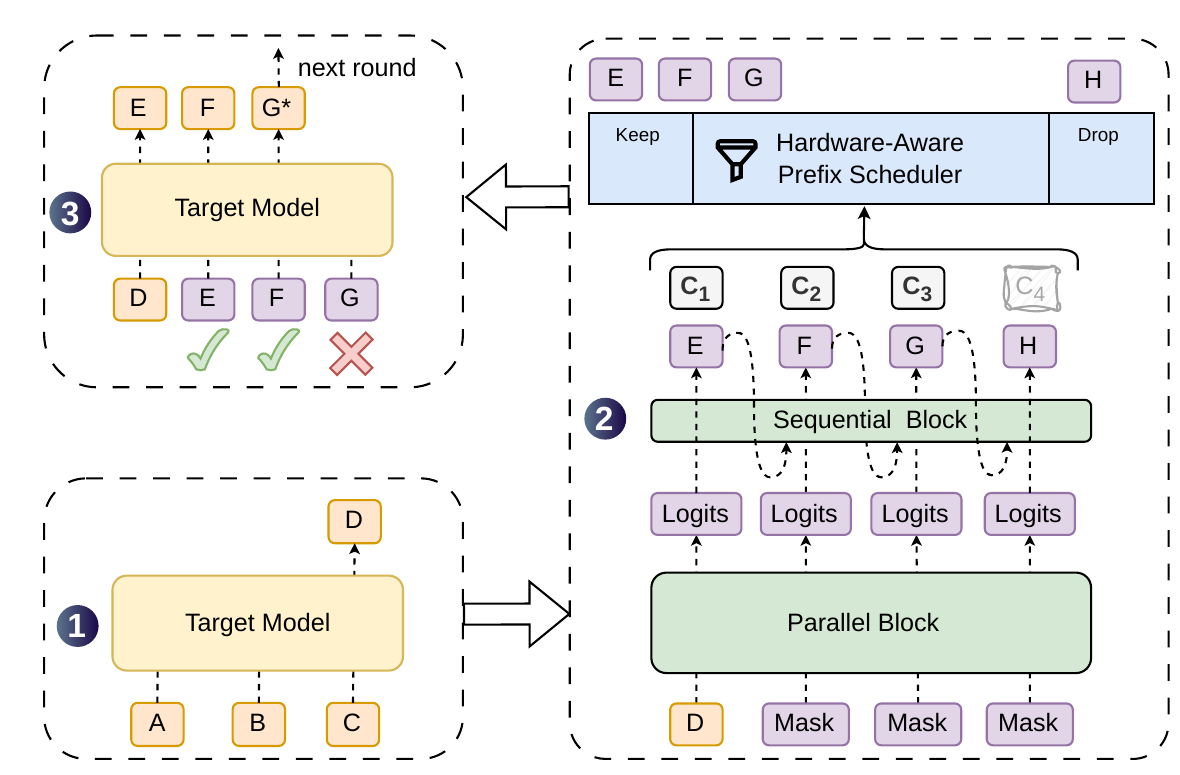
The released config keeps the head tiny: a draft network of three MoE layers with mHC and sliding-window attention of 128, max block size . The sequential head comes in two flavors:
- Markov head — first-order, memoryless: position conditions only on the immediately preceding sampled token. Cheap, and scales to large vocabularies. Once position 1 samples "of", the Markov head boosts "course" and suppresses "problem" at position 2 — exactly the collision the parallel drafter couldn't avoid.
- RNN head — carries more history than the memoryless Markov variant, at a little more cost.
The shipped drafter, "DSpark-5", uses the Markov head. It keeps almost all of the parallel drafter's speed — drafting latency is still nearly flat in — while recovering the acceptance rate a fully-parallel block throws away.
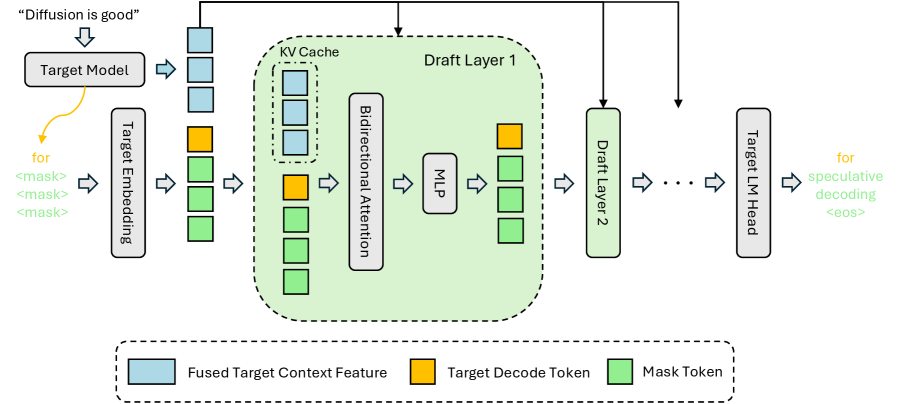
The parallel backbone is DFlash (ICML 2026), which fuses the target model's context features into the draft model's KV cache so a single forward pass can predict the whole block:
On the offline metric that isolates draft quality — macro-average accepted length per round, target models Qwen3-4B/8B/14B at temperature 1.0 across the DeepSpec eval suite — DSpark's semi-autoregressive drafter beats both the autoregressive and the fully-parallel baselines:
Roughly +27–31% over the autoregressive EAGLE-3 and +16–18% over the parallel DFlash it's built on — the semi-autoregressive head recovers most of what pure parallelism gave up, without paying EAGLE-3's per-token drafting cost.
Component 2: confidence-scheduled, load-aware verification
This is the genuinely new lever. Bolt a confidence head onto the drafter, trained end-to-end and then post-hoc calibrated — the paper cares about calibration error (ECE), not just ranking, because the scores have to mean something. The head estimates per-position prefix-survival probabilities. Then a hardware-aware scheduler reads live engine throughput and chooses, per request, how much of the draft block to bother verifying.
The intuition: verification consumes target-model batch capacity, which is the scarce resource under concurrency. Spending it on a low-confidence tail token the target will reject is pure waste. So trim the block to its confident head when the system is busy, and verify everything when it's idle.
With GPUs underutilized, verification is nearly free — so the scheduler drops τ (try ), verifies the whole block, and squeezes out every accepted token it can. The length is chosen per request, from live engine load.
There's a real systems subtlety underneath the slider. To avoid GPU pipeline stalls — you'd need the next step's capacity estimate before the current step finishes — the scheduler approximates upcoming capacity using confidence-head outputs from two steps prior, while still sorting candidate tokens by up-to-date cumulative confidence. The two-steps-stale signal only sets the dynamic truncation length; the acceptance itself is always exact, so the lossless guarantee holds.
Calibration — not just ranking — is the reason this works. The paper's reliability diagram shows the raw confidence estimator already discriminates well (it ranks survivors above doomed tokens) but is poorly calibrated — a raw score of 0.8 doesn't mean an 80% survival chance. A scheduler that truncates on a probability threshold needs the second property, not just the first, so DSpark calibrates the head post-hoc and measures ECE. Once it's calibrated, the threshold means what it says: as it tightens, the acceptance rate among verified tokens climbs from roughly 76.9% / 67.6% / 45.7% to about 92.5% / 92.0% / 95.7% on Math / Code / Chat respectively — the scheduler is keeping the tokens that actually survive.
DSpark also studied how deep to make the drafter and how long to draft. Deeper drafters help up to a point (the released config uses three MoE layers), and accepted length keeps rising with proposal length where a fully-parallel DFlash block would have decayed — which is the whole argument for the semi-autoregressive design, and why is a sensible default rather than a hard ceiling.
What it does in production
DSpark-5 replaced the previous production setup (a static MTP-1 single-token drafter) on DeepSeek's own V4 serving engines. MTP-1 was the incumbent precisely because naively deploying a static multi-token drafter degrades aggregate throughput under high concurrency — the exact problem the scheduler exists to solve.
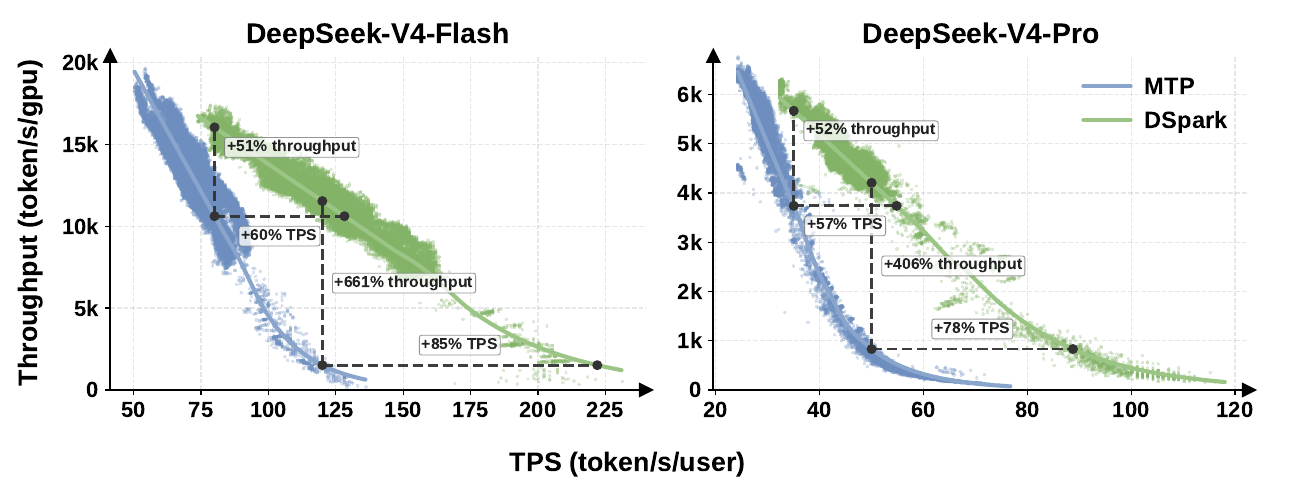
The honest reading of those annotations matters. At matched, practical throughput, DSpark accelerates per-user generation by 60–85% on V4-Flash and 57–78% on V4-Pro. The eye-popping "+661% throughput" point is a specific operating regime — a strict 120 tok/s/user SLA where the single-token baseline is already pinned at its operational boundary. The paper itself flags it as evidence of "extending the feasible interactivity frontier," not a representative multiplicative speedup. Don't quote +661% as a generic number; quote the 57–85% per-user range.
Where DSpark sits
| Autoregressive (EAGLE-3) | Parallel (DFlash) | DSpark | |
|---|---|---|---|
| Draft cost vs block size | grows linearly | ~flat | ~flat |
| Intra-block dependency | full | none | first-order (Markov head) |
| Acceptance decay | low | rapid | low |
| Verification length | fixed | fixed | scheduled per request |
| Lossless | yes | yes | yes |
EAGLE-3 drafts well but slowly; DFlash drafts fast but loosely; DSpark keeps DFlash's parallel speed, threads just enough sequential dependency back in to fix acceptance, and then adds the verification scheduler nobody else had. It's built directly on DFlash (the parallel backbone) and DeepSeek-V4 (the target), and ships open under MIT.
What I make of it
- The framing is right. Speculative decoding's latency formula has three levers, and "verify smarter" was the neglected one. A calibrated confidence head plus a load-aware scheduler is a clean, principled way to pull it — and because acceptance stays exact, it costs zero quality.
- The semi-autoregressive head is the quiet win. A first-order Markov head is almost free and recovers most of the acceptance a parallel block throws away. That's a better engineering trade than going back to a slow autoregressive drafter.
- Read the numbers carefully. The +16–31% accepted-length gains are clean apples-to-apples and should reproduce via DeepSpec. The production speedups are real but regime-dependent; the headline ratio is a boundary artifact, not a uniform multiplier. DSpark shifts the Pareto frontier — it doesn't move every point on it by 6×.
Built on DeepSeek's DSpark: Confidence-Scheduled Speculative Decoding with Semi-Autoregressive Generation (paper in the DeepSpec repo), the DFlash parallel drafter it extends (ICML 2026), and DeepSeek-V4, the target it accelerates. Weights: V4-Flash-DSpark and V4-Pro-DSpark, MIT-licensed.